The Story of the Info Pyramid:
Strategic Priorities and Tools in the Hunt for Information
Knowledge has always been the primary coin of education. In the 21st century, knowledge has also become the new oil that has surpassed the importance of former key economic factors.  Data is not only the newest raw material of business and culture but has become more important than capital and labor ("Data", 2011^). In the 21st century, knowledge has become the "primary engine of economic growth" (Birkinshaw, 2005^). In turn, questions have become the beating heart of the knowledge industry, pumping up facts that can be refined into solutions and startups. Enormous quantities of this "new oil" are free, and through awareness of city and university libraries, a much higher quality of "oil" is also available and already paid for and therefore also available for public use. The "story of the pyramid" is a strategic way to think about accessing and using this "black gold", this knowledge. This pyramid strategy applies to both the search for knowledge in general as well as Internet and Web searching. Since ancient times the pyramid has served as a symbol and source of enlightenment and creation to diverse peoples on multiple continents (Alford, 2003^; McCafferty, 2008^). This concept extends these metaphors of the pyramid into the idea driven practices of the global 21st century.
Data is not only the newest raw material of business and culture but has become more important than capital and labor ("Data", 2011^). In the 21st century, knowledge has become the "primary engine of economic growth" (Birkinshaw, 2005^). In turn, questions have become the beating heart of the knowledge industry, pumping up facts that can be refined into solutions and startups. Enormous quantities of this "new oil" are free, and through awareness of city and university libraries, a much higher quality of "oil" is also available and already paid for and therefore also available for public use. The "story of the pyramid" is a strategic way to think about accessing and using this "black gold", this knowledge. This pyramid strategy applies to both the search for knowledge in general as well as Internet and Web searching. Since ancient times the pyramid has served as a symbol and source of enlightenment and creation to diverse peoples on multiple continents (Alford, 2003^; McCafferty, 2008^). This concept extends these metaphors of the pyramid into the idea driven practices of the global 21st century.
 Knowing how to pump (question), refine (understand) and use (compose with) this oil to make new knowledge products using the magical range of the digital palette then has considerable value. As the yin-yang symbol on the right implies, for many millennia people have thought deeply about many different kinds of systems that synergistically feed and build each other; thinking is one of them. As the strobing lub-dub of the question marks within the animated graphic on the right imply, the heart pumping action of questioning and searching drives an endless cycle of eventual understanding and then new compositions with new conclusions that yield new questions, new searches. The digital age has vastly amplified the power of the pump. It also continues to exponentially increase the quantity and quality of the data far faster than society has enabled people that can run the pump.
Knowing how to pump (question), refine (understand) and use (compose with) this oil to make new knowledge products using the magical range of the digital palette then has considerable value. As the yin-yang symbol on the right implies, for many millennia people have thought deeply about many different kinds of systems that synergistically feed and build each other; thinking is one of them. As the strobing lub-dub of the question marks within the animated graphic on the right imply, the heart pumping action of questioning and searching drives an endless cycle of eventual understanding and then new compositions with new conclusions that yield new questions, new searches. The digital age has vastly amplified the power of the pump. It also continues to exponentially increase the quantity and quality of the data far faster than society has enabled people that can run the pump.
The search strategy is simple to explain; start at the top layer of the information pyramid and work downward. In keeping with much current naming of Internet phenomena beginning with an "i", it might be titled the ipyramid. The challenge is in the details about what the layers represent and what search tools are available at each level, which the thoughts ahead will explore in depth. Such methods are critical skills for the Look stage
of problem solving, the
problem processing stage for sifting the data of the information explosion in order to deal with problems and questions. As the general strategic thinking ability of children grows quickly from almost nonexistent in the first years of school to almost adult-like by age twelve (Winsler et al, 2006^), teaching strategic approaches to digital searching has great potential from elementary grades upward. Among all searchers in the general population, once search skills become effective there is an annual doubling in the number of questions asked and searched. Acquiring the initial skills though is expanding much slower; the number of new Web searchers expands at around 6% a year (Goodman, 2011^). To help expedite the needed growth, the document is divided into three major sections: the layers of the information pyramid, the geography of the Internet, and intellectual skills needed for making the most of the information pyramid.
The number and quality of the iPyramid tools, the search tools of the Web, are significant and yet still exponentially growing in capacity. The stored bounty of the information explosion (Houghton, 2012^) grows at a rate of 23% per year (Hilbert & Lopez, 2011^) and has done so for decades. To make effective use of the tools and the bounty requires inquisitive and probing minds that are both adept at the full range of higher order thinking skills and growing in number as exponentially knowledge is expanding. The
best hunting strategy ought to make the beginning point of the hunt the potentially
richest and most useful place available and then lead questioners onward through additional layers of resources. The linked web pages (noted below) will organize key search system tools into the pyramid's three
major divisions: brains, book shelves and drives.
This
page not only gives greater depth to the overall concept, but leads to other Web pages with numerous and unique search systems divided in major divisions, categories and sub-categories. The pyramid model also helps the teaching and recall of
the sequence for using this strategy. It also serves as an antidote to the idea that one search engine, such as Google's or Bing's, is sufficient for all information hunting needs. Though the information pyramid pages lead to numerous different types of search engines, "more than 35% of all searches happened on non-search engines" (Goodman & Green, 2012^), including such types of sites as ecommerce (e.g., Amazon) and social networking (e.g., Facebook). This Look stage of hunting for information is the first part of the LEAP
problem solving process, which in turn is part of the larger CROP model for
problem processing, all of which is explained in the basic idea section and other header branches above.
A strategic approach is defined as a planned or structured sequence of activity or the use of priorities to select some choices and ignore others (Davidson, 1991^). As important as cognitive-guided instruction should be, research indicates that children and adolescents commonly persist in using relatively ineffective strategies even when others are available (Siegler & Stern, 1998^; Winsler). Conversation with reference desk librarians has indicated that ineffective information search patterns persist throughout adulthood as well. Further, some 15% of even adolescents still do not apply strategic thinking (Winsler). That is, teachers must persistently instruct and monitor strategic approaches to provide sufficient support for changing habits, which applies to strategies in all content areas, not just in the strategic recommendations of digital search discussed here.
Given the frequency of ineffective strategies in use, inventing and teaching memorable models for strategy becomes significant in developing a way to recall persistently effective approaches. To assist with this effort, the model of a pyramid can prove useful. Begin by imagining a three layer pyramid. This pyramid can be used to categorize the three major ways in which our culture currently stores
information, making it an information pyramid. It is possible to stack these resources
in the order of how much human intelligence is applied in the storage of
the information and in the interface to the information. In this model, the best view
and the best quality resources are at the top of the pyramid. At the top
searchers hunt for the person with the best brain for your needs. In the middle hunters seek
the best publications or resources that must be retrieved from specific places on book shelves. At the base the quest is for the best things which are
stored electronically on various drives such as hard drives and other storage
media.
At this bottom or base of the pyramid is the greatest quantity of information but
too often requires significant filtering to identify quality within the great quantity of digital material.
The strategy chosen here is to Look in a top-down order through the tools of the layers of the pyramid. Two mnemonics for the layers have emerged. The order could
be called person, place and thing, take from the grammar rules for a noun. The sequence top down could also be called brains, shelves and drives. Within each layer, the resources can
be further stacked in additional sub-pyramids.
Clicking the relevant pyramids and layer links below will take you directly to the tools of these divisions. Definition and explanation of the categories is brief. Learning some of the systems within each category and subcategory are the best way to comprehend the nature of the categorizing.
Learning the details of the search system for each link begins by finding the help pages and examples within each search system site. As these collections of search tool sites are constantly evolving and growing their search capacities, it is useful to revisit the help pages with some regularity to look for changes and improvements.
The Layers of the Pyramid

The Top
Click this link, Top of the Pyramid (the Person or the Brains layer), to search for the minds of
those with the most expertise in your question or problem. This same layer also has links to sites that collect questions and attempt to connect them with those who can answer. This layer of tools also represents the brains of those who serve
as librarians and other local information specialists who specialize in assisting with information
retrieval. A key advantage of communicating with the right person is that they
can interact with you in an interactive discussion that redirects effort in more effective ways. One of the unique contributions of the Internet is the number of ways it enables finding and interacting with people, a reach extending from local to global. Yet, this is also the most neglected layer of the three, though when successful, the most useful place for a search to begin.
The boldfaced categories and subcategories of the Brains Layer page lead to a range of search tools for finding the contact information of people. Each of these Web sites opens to its home page which contains links to define and explain itself. Consequently, the best way to learn about each of them is to click on the links in the categories, then click the site's Help link. The Experts group of Web sites allow users to enter questions and have them answered by people of some interest and expertise in the topic, or those with none. Yahoo Answers allows anyone to respond, without any prequalifying of expertise. The Experts Exchange for IT requires payment for services, with a consequently much higher level of quality to their service. The category of Web Messaging Systems has been the most innovative with new designs constantly emerging. The microblogging category is the most recent, perhaps best represented by Twitter, though facing challenges about how to use it in non-trivial ways. Microblogs are made up of messages that are no more than 140 characters, a length set by the maximum size of cell phone text messages. This makes them useable from a computer or a phone. These searches will lead to comments written by people just seconds or minutes ago. The databases of the White and Yellow Pages categories provide the more traditional phone and postal address information, but increasingly they will need to contain Internet phone system numbers, such as those created by Skype and others for free calls over the Web.
The Internet gives inquirers and researchers unprecedented
direct access to experts around the world through a wide range of tools. Human intelligence can do what
no other form of information storage can do for you, intelligently interact.
Unlike a book or Web page, a person can tell you that your question does not make sense and can help you re-work the question. If the person cannot answer you
in a sentence or two by voice or email they can still put you on a useful
path. They can cut short the reading of dozens or thousands of books by
telling you a small number of books or resources that you need to study
to understand how to proceed. For example, if you were interested in the
theory of relativity you could begin to look for this phrase and find it
referenced in thousands of articles and books. The expert however could
tell you that one book nicely summarizes all the basic information on the
topic and that two articles sum up the most current thinking since the
book was written.
Experts, however, are not a perfect solution to information needs.
They might not be conveniently located in a nearby building or community.
They might not use electronic mail. They may not be able to respond to
your question or at least not in any time frame that is useful to your
immediate needs. They may charge for their services as consultants and
employees of information businesses. They of course could also tell you that
you are wasting their time with a trivial question to which you can find
the answer in a course textbook, dictionary or encyclopedia. They could
dislike the direction of your work, be heavily biased or for other reasons try to prevent
you from proceeding. They might not be the experts that they believe themselves
to be. Further, experts can disagree and the newer the idea and the more
controversial the topic, the more experts you must consult to cover the
range of ideas being considered for that issue. However, whatever the disadvantages
of experts, on average, starting with them can provide far greater mileage
than the lower two layers of the pyramid.
The Middle
Click this link, the Middle of the Pyramid (the Place or Bookshelves layer), which is generally the next
best layer to visit. Here you find the places where books, articles, movies,
videos and other physical forms of information are stored. These physical
storage formats include paper and plastic (film, microfische, audiotape,
videotape, CD's, etc.). At some point in its storage that means that all
these formats are stored physically on shelves.
The boldfaced categories and subcategories of the Periodical set provide indexes to the magazine and journal categories. For example, Google Scholar searches for articles while providing the number of the times a work has been cited by other scholars. The Bookshelves group lead to a range of search tools for finding information stored on shelves, usually periodicals and books. With one
web address, www.loc.gov, an information seeker can be combing through
the Library of Congress and its over 25 million books, which is just part
of its collection. Google Books not only searches by title, but with increasing frequency allows users to search for words within the book as well as read all or selected parts of a retrieved book. General Reference is a catch-basin for a wide variety of other forms of informatio that are stored on shelves whose content go beyond that of periodicals and books.
Several layers
of intelligence were involved in the preparation and sharing the
information identified by this group of tools. These works have the advantage of having been refereed
or reviewed by others, often by other experts on the topic. That is, at this time in human history, information that is
stored on shelves is often superior in quality to web pages stored in the
interconnected hard drives of computer networks such as the Internet. Much
of this material can generally be faxed or shipped within minutes or days
from libraries and bookstores. These shelved publications are also a source
of names of experts. If they are still among the living, you can move to
the person layer of the pyramid and seek their contact information.
This form of information storage has its own imperfections as well.
This data is housed in buildings around the world. These Web-based information systems
can only tell you where in the world the resource is located. You then
must use various transportation technologies to move that work or publication
to your current location. This certainly takes time, sometimes weeks. It
often involves expenses. These transportation systems might include working
with InterLibrary Loan, the Post Office, UPS or Fedex or other overnight
delivery services, fax machines, copy machines and more. Library and information
scientists have observed that finding a citation to a work of interest
in this layer is only 1/7 of the cost in time and labor in getting the
book or article in the hands of the person who needs it.
Consequently, this information isn't kept just on the shelves. Many businesses
have found it profitable to convert the full text of this shelf material
to digital information and make it available online on the web. This well established trend shows that every form of information is moving to digital format to take advantage of the global distribution and market of the Web. This will
be discussed further in the next section.
The Bottom
Click this link, the Base of the Pyramid (the Drives or Things layer), which represents information
shared through the Internet and stored on computer hard drives and other computer based mass storage systems.
By clicking the pyramid symbol above, a large set of online tools for this searching in this bottom layer will be revealed. The categories within this layer can also be thought of as a sub-pyramid of organized data.
The boldfaced categories and subcategories of the Drives Layer page lead to a range of search tools for finding information stored on the hard drives of the Net. The Pro category generally represent the work of professionals and their businesses, information that is often duplicated are adjusted in minimal ways for both paper and Web formats. The Reviewed Web Information links lead to databases of reviwed Web sites, information that generally provides some sort of critical analysis and evaluation criteria. The Subject Catalogs division provides convenient access to presorted information. It is the same role that library catalogers provide in appropriately finding and shelves new works of information so that related knowledge can be found as a set. The Robot Collected sites provide a representative subset of the diverse set of approaches for using software to visit, collect, index and make searchable the data stored on the hard drives of the computers of the Internet.
Using the Pyramid Toolbox
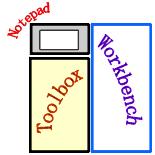
Clicking any one of the pyramid symbols above each section, instead of the link within the opening paragraph of each section, reveals the full Pyramid Toolbox. As the headings above described each of the three layers of the pyramid, an icon above the section was provided. Each icon led to the information pyramid's workroom or workshop for searches. This workroom is broken into three major divisions or windows or web pages. The toolbox area can display any of the three layers of the pyramid's tools: top, middle and bottom. No matter which layer is showing, the bottom lines of this layer have links to each of the other layers. Think of this as three shelves of tools that can be brought into view in a instant. The workbench area is where a particular tool from the toolbox will be displayed for use. The notepad area is to encourage the taking of notes, about search terms being used, or ideas copied from a web page. This area may be to small for any, but it serves to remind searchers to open a word processor window to capture ideas as the hunt proceeds. A "further directions" link above the notepad describes this info-hunter's workshop arrangement in greater detail.
The 3 layers are also described by characterizations other than top, middle and bottom. "Person, place and thing" helps connect the idea to a mnemonic that has been in the heads of many since childhood. "Brains, bookshelves and drives" helps connect the pyramid's organization with the physical location of the information.
Summarizing the Information Pyramid
There is an interconnectness between these three layers that should not be
overlooked. The base and the middle layer are cross-connected to its top layer.
That is, web pages are also more than just a resource for their content
or ideas. These files stored on hard drives are also a source of the names
of experts, not just web page content. Further, there are two distinctive
layers to the web, the "deep" web and the "shallow" web. On the web, the
area of greatest quantity, the deep web, turns out to also be the area
of highest quality.
No matter which layer or zone stores the information, its digital format
brings major advantages. If the information is stored in a computer which
is accessible through the Internet, access can be extremely fast. You might
find the real thing, that is the complete thing (book, article, image),
not some citation that points to the real thing located on the other side
of the world. The information could also be in other electronic resources
you already have paid for, such as an electronic encyclopedia on a compact
disc or information created personally in a folder on your desktop hard
drive. Further the information arrives in a format that makes it easy to
edit, copy and fit into other publications. You can quickly tailor this
incoming information for a variety of needs. Computer based information
is often among the most current data available, because it costs so little
to update or make changes to it once it is stored electronically.
The Geography of the Internet
As geography is the study of the distribution of things, maps of physical geography and animal populations provide access to special resources within the complexity of their patterns. Many other patterns of digital distribution have also been envisioned and mapped; such designs help in understanding structure and function in cyberspace (Dodge, 2008^; Zook, Dodge, Aoyama, & Townsend, 2004^; Zook & Dodge, 2009^). The ipyramid is another way to think about this distribution of data. Another basic division of knowledge is the password protected data and the public data, the deep Web versus the shallow Web. The shallow Web can be further envisioned in terms of the density of its patterns into something like a bowtie. The Web though changes much more rapidly than physical structures or animal populations in an information life cycle that also adds to our undestanding of Internet use.
The Deep Web
The phrase "deep web" began as a way to describe information in networked
databases that could not be indexed by the standard public search engines of
the Web. The company BrightPlanet (BrightPlanet, 2001)
claimed to have identified some 350,000 specialty databases that are not
indexed by standard web search systems, and could therefore could be described
as hidden. Once information is in databases, it takes a query or search
strategy to point to it, not a static web address. But there is other information
that is not being indexed by the public or free search systems, notably
any set of documents kept behind passwords and access fees.
The deep web
is often the electronic copy of the most commercially valuable portions
of the middle layer of the information pyramid. Fortunately, this perception
of the information being "hidden" is a misrepresentation of reality. Our
library system and its reference librarians provide an easy and well-lighted
walkway into the database and commercial areas, though some libraries have
budgets which pay the access fees to more of the private or commercial
layer than others. Several web sites also provide various approaches to
searching
the databases of the deep web.
How deep and big is the deep web? The BrightPlanet estimate was that the
deep web in 2001 was over 550 billion documents or web files (BrightPlanet,
2001), in contrast to the shallow web of some 2.1 billion pages. This
simple count of files greatly obscures the real size comparison. The deep
web files contain the full text of lengthy articles and books. The shallow
web is made up of significantly shorter web pages, often just a printed
page or two in length. The deep web is at least hundreds of times larger
and could easily be thousands of times larger than its cousin, the shallow
or surface web that the public frequents most often.
The Shallow Web
The shallow web or surface web represents the public portion of the Internet's hard drives.
It is similar to the deep web in its rapid growth rate. It is also qualitatively
different in important ways from the deep web in its interconnectedness.
The growth rate of the shallow web is significant. Estimates in the
fall of 1999 put this part of the Internet at over 800 million web pages
(Kiernan, 1999). In July of 2000, the number was
reported to be near 2 billion. Though the shallow web consists of a mere
2 billion web pages, current estimates have it growing at the rate of 7.3
million new web pages a day (Murray, 2000).
If the daily growth rate held steady, the public web will have reached
a staggering annual growth rate of over 2.6 billion pages a year. The web in the fall of 2001
did not meet their estimates
of some four billion pages, which called into question either their daily net
growth number or their capacity to keep up. In 2003, the major search engines
of Google and All the Web finally indicated they had indexed between 3 and 4
billion pages. In 2007 a report estimated some 30 billion pages (Pandia). In July of 2008 Google reported that it had indexed over one trillion Web pages and still did not have it all (Google). However, growth of the web with new pages is just one part
of the turbulence of the web. Researchers should also take into consideration
the additional change provided by web pages being updated and obsolete
ones being deleted.
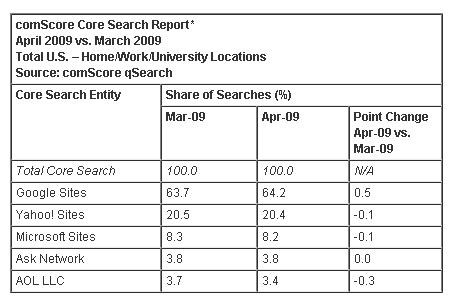 Given the thousands of search engines, how does one set priorities in learning the numerous features of various search systems well? Dignan's (2009) data in the table of this paragraph helps clarify the current situation. The marketplace continues to vote through its usage that Google's search systems represent the best yet available. Google's stated corporate goal is provide access to all the world's information, meaning all the layers of the information pyramid. But Google is a long way from delivering on that goal. Searchers will also need experience with other search systems beyond having baseline knowledge of Google's search tools (See also, Google Search Posters, Google Search Classroom Activities.) Other search systems includes knowing the search systems of the libraries that are within reasonable driving distance from your home and place of work.
Given the thousands of search engines, how does one set priorities in learning the numerous features of various search systems well? Dignan's (2009) data in the table of this paragraph helps clarify the current situation. The marketplace continues to vote through its usage that Google's search systems represent the best yet available. Google's stated corporate goal is provide access to all the world's information, meaning all the layers of the information pyramid. But Google is a long way from delivering on that goal. Searchers will also need experience with other search systems beyond having baseline knowledge of Google's search tools (See also, Google Search Posters, Google Search Classroom Activities.) Other search systems includes knowing the search systems of the libraries that are within reasonable driving distance from your home and place of work.
As dominant as one company can be at any point in time, the future of search may very different. Mobile searchers, those searching the Web from smartphones with Internet access such as the iPhone, are moving from Google search to many specialized applications designed exclusively for smaller screen display which are more focused in their content, easier and faster to use (Hiner, 2009). Further, real-time search systems ignore Web pages and specialize in providing access to up-to-the-minute information. These systems draw information from a range of real-time systems such as microblogging sites like Twitter or social networking sites like Facebook with its status updates, pushing a continuous stream of updates to a user's screen. Just as one search system closes in on offering access to every Web page, educators may find they need to teach multiple search systems, each requiring some new form of reading ability that rquire the use of some unique search methods.
The Shape of Information
What is most special about the shallow web is the openly revealed nature of
the linking
among its web pages. Search engine technology enables researchers to "see" into
how human beings interconnect their ideas. This has always been possible on very
small scales such as minute portions of the neuronal connections in the brain,
or in larger scale with groups of people or an interrelated set of journal articles. In contrast, search
engines and the public or shallow web enable studies to be done on the
relationship of billions of pieces (web pages) of information. The patterns that
are emerging here may be typical of not only of information found in these other
layers of the pyramid, but of many types of complex networks.
What do we know
about the shape of information? On average, any web page is but a few clicks from
any other page. Some research has estimated that the average web page contains
from between five (Murray, 2000) to seven (Kiernan,
1999) external links per page. The number of links between any two
pages on the web can then represent the diameter of the shallow Web. This
diameter was first estimated at around 19 clicks (Kiernan,
1999). In this view the web could be seen as a well stirred pot of spaghetti
noodles, each noodle representing a path of many connections between web pages.
Later work showed that the distribution is not so evenly stirred. The web has
neighborhoods that are highly connected and those that are not. Broder and
others developed a model that reminds one of a bow tie with a few loose threads
hanging from it (Broder et al, 2000). The knot of the bow tie represents a
highly connected core or neighborhood of some 30% of the web. The left wing of
the bow tie stands for the 24% of the web which has connected to the core but
which lacks connects back from the core. These could be thought of as new web
pages not yet discovered by authors with web pages in the the core. The right
wing of the bow tie is the 24% of web pages which are connected from the core
but lack connections back to the core. The loose threads and tubes which hang
from the bow tie represent the 22% of information that is made up of
disconnected web pages. Of the pages in the highly connected core, Broder's team
showed there is an average of 7 degrees of separation, otherwise the diameter of
the paths is 16. However, nearly 75% of the web is either not connected or
poorly connected to other bits of information.
The patterns of information in
the other layers of the info pyramid is much less well known. This is not to
say that the deep web lacks linkage, but the linkage is done through bibliographies
and footnotes making movement through these connections much more slow
and cumbersome. Because these links are not computerized and therefore not
available for rapid computerized measurement, the actual pattern in the deep web
cannot be seen directly but only can be inferred from the patterns appearing in
the shallow web. The deep web can be liken to the slower pace of life in
the colder deep ocean, with a seemingly sluggish rate of change in comparison
with the rapid growth and decay in the hot shallow waters close to continental shores.
Both have important value. It is an even further reach to suppose that social
networks and paper citation trails follow the same patterns. Yet, Barab�si's
work (2001) does show that the non-scaling patterns of information in the
shallow web do match with many other forms of complex systems. In playing with
the perspective of these different patterns, our minds gain a deeper
understanding or the wide range of possibilities of the Internet and the web (ManicLink).
Improving
The Life Cycle of Web Information
An examination of the ecology of the shallow web and how information
life grows, gains value and dies there is needed to understand its life
cycles. Life first grows in the shallow web because anyone can grow something
there by uploading a file in seconds. Because of this, it is true that
the shallow web has much seemingly irrelevant information about hot cars,
birthday pictures and email flame wars. That observation misses seeing
how the information that is valuable becomes known and how it grows into
stronger and more useful information. Just because a web page exists does
not mean that many people pay attention to it or value it.
People make
links between web pages when they perceive that another web document does
an effective job of contributing to their own web page. It may be a contribution
of complement or a contribution of contrast and dissonance. Web authors
do not want too many links on their web pages, so there is an evolutionary
or Darwinian struggle as new more effective web links come along which
leads to the removal of less effective web links. As the author of a web
page makes these links, they learn things from the pages they link and
modify their own web page, making it more valuable. This contrast with
the deep web in which the original article cannot be modified, requiring
the author to write and publish a new article, a much more time consuming
and arduous process. Search engines have learned to take advantage of this
ecology. For example, the google.com search engine makes the priority of
its search listings dependent the number of links made to a given web page.
The pages at the top of its search listings have been prioritized by the
number of other web pages that have links to them. As those seeking further
links for their own pages use the top items from search engine hits, this further contributes
to the evolutionary rise of certain web pages and sites. The rich get richer.
The popular get more popular. This not the top down order of a cataloging system
but the bottom up emergent order of a social system.
Thinkers that discover new problems and compose new solutions often
must make a choice between publishing their work in refereed publications
which removes their work from the evolutionary struggle for value in the
web linked economy, or placing them in the shallow but public web where
the best information evolves to have the most links to other relevant works.
The deep web keeps its holdings separate from the direct links of the shallow
web. In the deep web appears designed for the interaction of a small group
of specialists. The surface or shallow web appears designed for a wide open
public "vote" on the merits of a given web page, the vote being a web author's
choice to link to a given page. This poses an intriguing and
deep problem. Can information scientists and scholars bring higher levels of interactive
life to the deep web and connect this dialog to the higher levels of interaction
of the surface web without undercutting
the very economic system that has built the deep web or detracting from the
democratic openness that has spawned the phenomena of the World Wide Web?
Many problems exists within the information at this shallow layer. The
information that becomes published in seconds may never have been qualified
by any other human as to the data's accuracy, currency, truthfulness or
a host of related concerns. Much greater responsibility is placed on the
hunter of this layer to not bring home tainted or rotten fish. Anyone with
the capacity to put the information on the Internet can remove it in seconds
too. You may tell others where to look, but it may have moved, been removed,
or updated or changed in some way that no longer suits your purposes. This
is in contrast to the deep web in which much of its information has a permanent
and stable home for decades.
In all fairness, there are many Internet or otherwise computer-networked
sites with carefully qualified information. This information can be extremely
relevant and useful. But you must look over Internet sites carefully to
make sure that they are legitimate, not a careful fake from someone who
might benefit from altered data or just someone enjoying a spoof of others
work. Cross checking this information against that found in other layers
of the pyramid is the only way to validate or trust what you have found.
One can also envision a time in which the person, place and thing layer
will be collapsed into one layer, with all information universally available
electronically. But it is emphatically not here now and there are economic
forces at work that can keep this from ever happening.
Do remember to keep track of where the information came from in this
electronic thing layer. That is, not only copy the information you need,
but copy its references. The format of such references may seem quite different
from citations in the middle place layer. References for a web page should
include the URL or web address, the author of the web page if he or she
can be found and the institution that hosts or provides the web pages.
Carefully follow the top-down path of person, place and thing, capturing
the best of what is available at each level. Summarize the information
where you can. Copy and move needed data to files that are saved
to a data storage device such as a USB drive. Compensate for the weaknesses of information stored in
one layer with the strengths of ideas and concepts found in the others.
The strength of our global culture's information pyramid comes from the
differences in each layer. Utilizing the full scale of the pyramid adds
strength and depth to your work in addressing the problems and questions
of your lifetime. In turn, readers become thinkers that add strength back
to the pyramid. This is done by mixing information that comes from your
own experience with the information found in new situations and seeking
its performance and publication.
Intellectual Skills for the Information Pyramid
The information pyramid strategy that has been explained helps with two
important features of information literacy: knowing how knowledge is organized
and how to strategically go hunting among its different major layers. For further
background, also explore Fowler and Simpson's tutorial on information literacy
skills (2003). There are other feature of information literacy that also needs to be much better
known, including reading skills for the digital age, human logic and processing logic. Though after a certain age we presume much about reading skills, in fact, many skilled adult readers of paper technology have much to learn about Web reading. The needed logic consists of certain mathematical terms that
can be applied to computer stored knowledge and also consists of processing
logic, otherwise known as higher order thinking skills with an accent on critical thinking.
Reading & Writing Skills
A special general challenge for readers is to recognize that a transition is underway between paper and digital systems. Some reading skills overlap the world of paper publications and the world of Web publications. Other reading skills are new and are still being invented through the innovations of web design. An especially valuable feature of information search activity is its dual role in a simultaneously reinforcing and teaching writing and reading activity. Nothing happens until something is written, an act which often return additional related vocabulary.
Readers of text and many forms of media benefit from solving the problems of what might be called traction and bias. Traction requires settling in to a reading in stepwise fashion using skim technniques to grasp the highlights of a text and scan techniques to find specific words. This should be followed with reading methods such as SQ4R (Survey, Question, Read, Recite, Relate and Review). Information in any format must also be weighed for varieties of bias that call into question the relevance, currency and accuracy of the information.
Exploration of the new digital skill sets can be divided into three areas of activity: pre-reading, comprehension and engagement, and meta-reading. Pre-reading skills include: Web search skills; browser display management to elliminate distractions; and control of the window width to support efficient line scanning. Comprehension and engagement skills include: learning the systems for writing on the Web page during the reading event; having sufficient time to build up background knowledge; learning in-page Web searching techniques; mastering embedded Web searching for any word phrase not understood; and pairing text ideas with an image search for the same term to enhance the mind's dual encoding of information. Meta-reading means thinking and making decisions about the reading process while the reading of information is underway. For example, effective decisions must be made about whether to stay with a particular page or jump to something new. Other high level decisions include: activation of a browser's read aloud features; capturing segments or entire compositions to build a personal library; mastering tabbing and tab grouping of Web pages; and making decisions about meta data and applying metatags when files are stored. The examples provided here are just some of the elements involved in these three major divisions of reading activity.
The valuable role of information search in expanding everyone's language arts capacity deserves additional emphasis. Every search expands the definition of other related keywords, a running thesaurus activity. Every reading provides new words that can initiate the next search with the sub-second response time of right clicking on a word in the reading. The response rate is as fast as the reaction times of video games of which youth are so enamored. The capacity to be hooked on search just as youth are hooked on games is one more reason to make Internet capable computers routinely available on student desks both at school and at home. A computer's presence in an environment of study about some aspect of the world must be having a significant impact on world's reading and writing skills that the scholarly literature has yet to find a way to measure.
The topic of Web reading and composition skills is much more vast than can be fully explored here. As the numerous details of digital language arts skills go far beyond the scope of this composition, it is best to recommend other more focused readings on these topics. The articles Reading Challenges: the Paper to Digital Web Transition (Houghton, 2009) and Breakaway Literacies (Houghton, 2009) expand significantly on the ideas introduced so briefly in this section.
Boolean Logic
As an extension of this pyramid strategy, searchers must also understand
and use the terms of Boolean logic (e.g., AND, OR and NOT) to narrow and
expand their searches as needed. Failure to know and use Boolean thinking
leads to a significant number of failures in information retrieval (Weise,
2001). Sometimes these terms must be entered manually, sometimes
the search pages are set up with data entry boxes that carry out these
functions without manually entered the Boolean logic terms. Sometimes the
search engine assumes OR and sometimes AND relationships in the search
strategy. Knowing more about Boolean and more about the degree to which
different search engines handle Boolean increases the searchers effectiveness
(University of Albany, 2001).
Searching for "CATS OR DOGS" retrieves more information than
searching for "CATS AND DOGS" because or means either condition
is acceptable while and means both conditions must be true. The
more conditions that must be true before a citation or article is retrieved,
the less information that will be found. The terms AND and NOT are used
to narrow a search when too much information or too irrelevant information
is retrieved. The term OR is used to broaden a search by connecting a set
of synonyms for a concept. A thesaurus is a handy tool to meet this need.
Through the use of parentheses, complex nested sets of logic can be arranged
(cats OR tigers OR lions OR felines) AND (dogs OR wolves) NOT pets. More
attention needs to given to those resources that teach Boolean skills to
both school age children and adults as well as resources that show how
to apply those skills to searching databases and the web (Houghton
& Houghton, 1999).
Simple techniques can have significant impact.
For example, BrightPlanet estimated that by using six to eight appropriate
terms per search, the amount of irrelevant information retrieved can be
reduced by over 99% (BrightPlanet, 2000). This yields a search strategy then that could be called push to failure. That is, the searcher should keep adding additional search terms and special qualifications to the search (such as date range) until the results yield zero. At this point, the searcher should then selectively drop off a term or condition or two so that just a small highly qualified set of items in a search list remain.
As beneficial as it is to know basic Boolean logic, effective net searching
requires more. Certainly knowing basic guidelines on a number of techniques
is important (Whitley, 2001). Examing the help pages of
web search engines is a quick way to learn many valuable search commands and
techniques. If instruction at
this phase of research is really going to be enhanced by teachers and the
team of educators that help them, some new elements must be added to the
basic patterns of our compositions. The bibliography for every composition
should include more than the list of authors and sources. The bibliography
should also include a listing of the search systems that were used and
the search strategies employed at each one. This information is most important
during the formative stages of writing, and should be one of the first
elements checked by teachers and writing centers that assist with rough
drafts. This enhancement would be equally beneficial for the bibliography's
of professional publications.
It is also valuable to be able to find the
community of people interested in a particular topic by searching for which
pages have linked to a given page. Some of the search engines have a command
called link: that makes this easy. For these examples use Google,
Alta Vista or All the Web. Try link:www.whitehouse.gov or link:www.wcu.edu/library/
which return the web pages which link to the searched for page. The specialized commands are not the same for every search engine, requiring one to search for the search engine's name and "short cuts" or "cheat sheets", example, Google "cheat sheets". Techniques for searching by country and detailed cheat sheets for more specialized commands can be found in this eCROP blog posting, finding info by Web Country codes.
These Boolean terms in conjunction with specialized commands help us control the quantity and specificity of
the information that is sought. These terms cannot directly address the
quality of what is found. There is no substitute for thinking.
Semantic Thinking
Searching using simple search strings of text characters that can be enhanced by Boolean logic only goes so far. The search systems up to May of 2009 were based on matching a pattern of text characters with text in existing Web pages, then prioritizing and presenting the matches based on an evolving set of criteria. As the Web continued to dump information in helter-skelter fashion dissassociated with related information located on other Web sites and in commercial databases, new methods were envisioned that involved higher levels of reasoning and connectedness (Berners-Lee, 1998). Search engines were needed that went beyond pattern matching to understand the semantics of data, engines that both recognized the meaning behind a string of characters that makes up a word and recognized the relationship of data found at many different locations. Such systems can be thought of as a cross between a graphing calculator, a reference library for science, math and finance and a logic engine. From a knowledge of basic facts and logical procedures, semantic systems can reason to some degree. If users can create the right search questions, such systems can generate new information by making logical deductions and carrying out mathematical operations based on that meaning.
The first semantic systems were announced in May of 2009. Google announced a product called Google Squared that by the end of May 2009 will take a search term and pull related data from multiple sites to build a table containing comparison information that will link each cell in the table to its source. See TechCrunch's video on Google Squared.
The WolframAlpha site has promised even greater semantic capacity. The WolframAlpha Introductory Video's demonstration of the initial capacity of the WolframAlpha search engine on day one of its public availability (May 15, 2009) is a powerful definition of semantic computing by example.
Left begging is the question of how to educate users to ask the right search query questions to generate solutions to real world problems. Strategies here though are not unknown. Like most topics, the more depth known about a topic, the more effective questions become. This adds further weight to the concern about mile-wide and inch-deep curriculum and value to the notion of long term student projects.
Critical Thinking
Being effective at finding information is not enough. Whatever information
is found, an intelligent weighing of the evidence is always needed. There
are certain basic aspects of qualifying information that apply to the use
of all three of the layers of the information pyramid. In every case you
must consider basic rules of evidence. This type of reflective attitude
is also known as critical thinking. The information literate person must
be able to evaluate the accuracy, currency and relevance of the data they
encounter. Evaluating relevance also means carefully weighing the reputation
of the source of the information at any level of the information pyramid.
Both oral communication and the web, the top and the bottom of the information pyramid, can be easily, cheaply and rapidly shared and distributed without any filtering by additional minds, such as editors, reviewers and specialists on the topic. Consequently, using information from the top and bottom layers requires a heightened sense of care in examining the accuracy, currency and relevance of information found there. Being more skeptical of these sources than paper publications is a healthy attitude for 21st century thinkers. That said, the general perception of paper publications being better qualified means that those with greater reason to persuade someone of something are likely to make their approach or attack through paper. A skeptical attitude is a good defensive stance for all sources of information.
Being effective at critically evaluating the quality of information is not enough. To effectively
use the information that has been found requires acceptable means to be able to
store, manipulate (e.g., copy and paste) and compose in a way that has
a positive impact on our culture, on those within it. At the mechanical
level, using information means having the digital skills to paraphrase
and copy information into different applications such as outline processors,
spreadsheets, graphic information systems and databases and then use these
tools for further and deeper analysis. In this age of multimedia, it also
means having the ability to go beyond text, to capture, cut, copy and paste
with audio, video, still image, three-dimensional images and more. It also
means having the ability to merge these multiple forms of expression in
the same composition.
Of even greater importance is the ability to use this information to
be able to make a point and sustain it with examples and supporting facts.
It means to be able to choose appropriate forms of sharing for a particular
audience, from the creation of essays and newsletters to video, from making
a speech to a stage performance. It means understanding Bloom's higher order categories about the unique nature evaluative thinking as applied to a social, legal or ethical question. Use the resources at hand. The walkway to many a college and community
writing center is as well-paved and well lit as the one to the library
reference desk.
Collaborative Search
Though Web search as a solitary activity is the most common experience of Web users, more expert searchers have reported carrying out collaborative search activities once or twice or month on average. Over 87% of these experiences (Morris, 2008) used the backseat driver model of 1 to 3 participants offering suggestions while watching over the shoulder of the person at the keyboard. About 88% of this same group had also participated in collaborative searches with off-site or remote sets of participants. As this group reported using the phone, IM (Instant Messenger) and email exclusively for remote communication, the interaction process can also be significantly improved through the use of software designed especially for Web conferencing.
Especially given the earlier discussion of the consistency with which children, adolescents and adults commonly persist in using relatively ineffective strategies, Web search, whether co-located or remote, is certainly one of those topics that could significantly benefit from team activity. One of the great benefits of group activity for all learning but especially for more difficult and complex topics is activity that shares new ideas, models good practices and enables joint discovery.
The search process breaks down into a series of steps which can be done in series by an individual or a team or distributed among participants who each have their own computer. The critical first steps is asking and reframing a question that clarifies the information needed. This is followed by selecting and imagining relevant keywords for the search, then skimming data for relevant information, selecting readings for in-depth reading to determine its value, copying and pasting results, synthesizing the results into some new composition, then evaluating the entire process. This process was first articulated as the Big Six Skills by Eisenberg and Berkowitz (1988) and designed to match stages of Bloom's higher order thinking skills. This approach overlaps heavily with other search models (Eisenberg, 2008). At each stage, the work can be done by one person or distributed among team members. Morris (2008) noted that when the expert group had their own computer, the group's strategy was either "divide and conquer" or "brute force". The former chose to divide tasks up among members while the latter worried less about duplication of effort, choosing to merge and sort out results at the end. It is curious that no teams chose to mix both methods.
Having some kind of search task table to identify which stages will using divide and conquer with what division of labor and which stage will be brute force would streamline those early decisions.
When all the members of the group or team are in the same space, a number of simpler choices are available for working the search process. A typical computer display screen works fine for 2 to 4 participants while large computers screens or projection systems enable much larger numbers. The primary limitation is the number of people that can effectively participate in contributing to the search at hand. This suggests that large group demonstrations such as as classrooms and lecture halls would benefit from a team or panel that works the process while others observe.
When some or all members of the search team are remote, then the limitation is the capacity of the Web communication software. Email is the least interactive of the commonly used choices but works fine where time limitations are not problems. IM can support team size groups but is about a third of the speed of voice communication. Phone sharing can limit the number of participants to two unless phone conferencing capacity is available. Though free Web conferencing software limits the number of participants from 3 to 6, it eliminates the problems of email, IM and phone, by combining all those features with many more, including the especially valuable shared whiteboard space. Web conferencing software also has the capacity to not only share out a view of the someone's desktop where the search is underway, but allow remote control of that screen by others as needed.
Composition
The process of gathering information really begins with a sense of need
and the construction of a question. There are certain basic signs which
would indicate that more information and knowledge is needed. Does the individual
or the participants in the research thoroughly understand the concept,
idea or situation that is being considered? Are there multiple conflicting opinions and reports? Does everyone agree with the
basic conclusion being reached? Has there been a real effort to dig for
new and related questions? This activity should also be seen as equal parts
of opportunity recognition and problem recognition.
Teaching Strategies
Teaching the information pyramid starts with awareness. A simple poster with a pyramid with two lines drawn through it to create three layers is sufficient to begin the conversation with a class of students. This knowledge should be combined with the information taught by the school librarian or media specialist. There is much to teach and much that is complex and new to all students that requires some planning. Those plans should include a sequence of introductions and practice activities that cover something from each of the three layers throughout the academic year.
The need for the knowledge summarized
in the list below, also known in information literacy circles as the big six, has long been heavily promoted by the professional library
associations (Bruce, 1997; Esenberg & Berkowitz, 1990; Eisenberg, Lowe, & Spitzer, 2008). The more effective learner and problem solver will:
- 1
Know when information is needed.
- 2
Know how knowledge is organized.
- 3
Know how and where to locate information.
- 4
Know why information is offered and from whom it is coming.
- 5
Know how to evaluate the accuracy, currency and relevance of information.
- 6
Know how to use information effectively.
The Information Pyamid also adds a top down strategy for information pursuit, creating the big seven.
- 7 Know how to hunt for information strategically.
For classroom dialog and interaction these seven statements
can be re-phrased as questions for class participants. For example, how do you know more information is needed? How is this knowledge organized? Can you show me how you hunt strategically?
Need a mnemonic device to learn and teach the info pyramid? Sing these words to the tune of children's song, Heads, Shoulders, Knees and Toes.
- Brains, book shelves, drives and think, drives and think;
- Brains, book shelves, drives and think, drives and think;
- Touch your mouse and keys and screen and link;
- Brains, book shelves, drives and think, drives and think.
Conclusion
How peculiar to be a member a global culture made up of an overwhelming majority of impoverished citizens that lack the capacity to pump and use an infinite supply of wealth. That is, one more time, some 1/3 of the world's citizens have created a system that produces infinite wealth and yet our thinking is locked into the behavior of those living in scarcity. This leaves most of the passengers on spaceship Earth without. The black gold gushes out beyond measure awaiting the simplicity of questioners able to refine it into usefulness. In short, the pumping action begins with empowering the learner and citizen of this age to
know a series of interlocking basic information skills, an empowerment that is significantly
increased by fluent reading ability.
For educators,
some pieces of this information literacy need addressing in every assignment
and project at every age level. For adults, using the information pyramid strategically
in the discovery and solution of problems becomes increasingly important
as the rate of change in knowledge and culture increases. This composition has
provided a novel model for addressing each of these steps, a pyramid design
which is in turn part of the larger CROP problem processing model.
In short, those handling the knowledge pumps need to know:
- What key criterion is used in stacking the layers of the Information Pyramid?
- What is meant by the Information Pyramid's top down strategy?
- What is the rationale for the Information Pyramid's top down strategy?
- What are some examples of different elements of thinking and their engagement with this model?
- What demonstrates mastery of one or more search systems at each layer of the pyramid? At each category? At each sub-category?
- How do answers and discoveries get communicated in globally digital ways that build collaborative teams?
Bibliography
Alford, A. F. (2003). Pyramid of Secrets: The Architecture of the Great Pyramid Reconsidered in the Light of Creational Mythology. Eridu Books.
Abreu, Elinor (Sep 11 2000). Diving
Into the Deep Web. The Industry Standard Magazine.
Barabási, Albert-László (July, 2001). The Physics of the Web.
PhysicsWeb.org. Retrieved on January 5, 2004 from http://physicsweb.org/article/world/14/7/09
Berners-Lee, T. (1998). Semantic Web Road Map. Retrieved May 16, 2009 from http://www.w3.org/DesignIssues/Semantic.html
Broder, A.; Kumar,
R.; Maghoul, F.; Raghavan, P.; & Bruce, C. (1997).The Seven Faces of Information Literacy. Powerpoint slides available at http://crm.hct.ac.ae/events/archive/2003/speakers/bruce.pdf.
Birkinshaw, J. (2005). Knowledge moves. Business Strategy Review, 16: 38–41. doi: 10.1111/j.0955-6419.2005.00378.x
Data, data everywhere. (2011, February). The Economist. http://www.economist.com/node/15557443
Dodge, M. (2008). An Atlas of Cyberspaces. Retrieved May 14, 2009 from http://personalpages.manchester.ac.uk/staff/m.dodge/cybergeography/atlas/atlas.html
Eisenberg, M. B., & Berkowitz, R. E. (1988). Information Literacy: Essential Skills for the Information Age. DESIDOC Journal of Library & Information Technology, 28(2), 39-47.
Eisenberg, M. B., & Berkowitz, R. E. (1988). Library and Information Skills Curriculum Scope and Sequence: The Big Six Skills. School Library Media Activities Monthly, 5(1), 26-28,45,50-51.
Eisenberg, M. B., & Berkowitz, R. E. (1990). Information Problem Solving: The Big Six Skills Approach to Library & Information Skills Instruction. Norwood, NJ: Ablex Publishing Corporation.
ERIC #: ED330364.
Eisenberg, M. (2008). Information Literacy: Essential Skills for the Information Age. DESIDOC Journal of Library & Information Technology, 28(2), 39-47. Available October 18, 2008 at http://publications.drdo.gov.in/ojs/index.php/djlit/article/download/288/182.
Rajagopalan,
Sridhar; Stata, Raymie; Tomkins, Andrew; & Wiener, Janet (2000). Graph
structure in the web. Retrieved on January 6 ,2004 from http://www.almaden.ibm.com/cs/k53/www9.final/
BrightPlanet, (2001). Online: http://www.brightplanet.com/deepcontent/index.asp
BrightPlanet (2000). Search Tutorial: Deep
Content. Online: http://www.brightplanet.com/deepcontent/tutorials/search/part1.asp
Davidson, D. (1991). Developmental differences in children’s search of predecisional information. Journal of Experimental Child Psychology, 52, 239–255.
Dignan, L. (2009, May 20) Microsoft to show off new search: Will it matter? ZDNet. Retrieved May 20, 2009 from http://blogs.zdnet.com/BTL/?p=18458
Fowler, C. & Simpson, B. (2003). Texas Information Literacy Tutorial
(TILT). The University of Texas System Digital Library. Retrieved on January
11, 2004 f rom http://tilt.lib.utsystem.edu/
Goodman, E. (2011, March 7). Q&A Search: Who, What, Where, When, Why & How. Search Engine Watch. http://searchenginewatch.com/article/2066005/QA-Search-Who-What-Where-When-Why-How
Goodman, E. and Green, J. (2012, March 28). Beyond Search Engines: The Brave New World of Retargeting Data. http://www.comscore.com/Press_Events/Events_Webinars/Webinar/2012/Beyond_Search_Engines_The_Brave_New_World_of_Retargeting_Data
Guernsey, Lisa (January 25, 2001). Mining
the 'Deep Web' With Specialized Drills. New York Times.
Hilbert, M. & López, P. (2011, February 10). The World's Technological Capacity to Store, Communicate, and Compute Information. Science. DOI: 10.1126/science.1200970. Retrieved February 11, 2011 from http://www.sciencemag.org/content/early/2011/02/09/science.1200970
Hiner, J. (2009). Google's biggest threat in mobile search: iPhone apps. Retrieved May 27, 2009 from http://blogs.zdnet.com/BTL/?p=18634&tag=nl.e539.
Houghton, R. S. (2012). The knowledge society: Surfing its tsunamis in data storage, communication and processing. http://www.wcu.edu/ceap/houghton/readings/tech-trend_information-explosion.html
Houghton, Janaye; & Houghton, Robert (1999). Decision
Points: Boolean Logic for Computer Users and Beginning Online Searchers.
Teacher Unlimited.
Kiernan, Vincent (September 9, 1999). As
Goes Kevin Bacon, So Goes the Web, Researchers Report. Chronicles of
Higher Education.
McCafferty, G. G. (2008). Alteptetl: Cholula's Great Pyramid as 'Water Mountain'. L. Steinbrenner, , B. Cripps, M. Gerogopoulos, & J. Cass.
Morris, M. R. (2008). A survey of collaborative web search practices. Conference on Human Factors in Computing Systems. Proceeding of the twenty-sixth annual SIGCHI conference on Human factors in computing systems, Florence, Italy. New York, NY: ACM, 1657-1660.
Murray, Brian H. (2000). Sizing
the Internet (pdf file). Corporate Report: Cyveillance.
Siegler, R. S., & Stern, E. (1998). Conscious and unconscious strategy discoveries: A microgenetic analysis. Journal of Experimental Psychology: General, 127, 377–397.
University of Albany Libraries, (2001). Boolean
Searching on the Internet: A Primer in Boolean Logic.
Weise, Elizabeth (2001). One
click starts the avalanche: Buried in information? Smarter searching comes
to the rescue. USA Today.
Whitley, Betsy (2001). Help
Students "Search Smart" on the Internet. Faculty Forum, Vol. 14, No.2.
Winsler, A, Naglieri, J. & Manfra, L. (2006, July-September). Children's search strategies and accompanying verbal and motor strategic behavior: Developmental trends and relations with task performance among children age 5 to 17. Cognitive Development, 21(3), 232-248.
Zook, M. & Dodge, M. (2009). Mapping Cyberspace. Entry in The International Encyclopedia of Human Geography (Rob Kitchin and Nigel Thrift, Eds.). Elsevier Science.
Zook, M., Dodge, M., Aoyama, Y., & Townsend, A. (2004). New digital geographies: Information, communication, and place. Geography and technology, 155-176.
For more, explore this Google search, "effective Web searching".
Short link to the frameset of these pages: http://tinyurl.com/o7lb98
Parent frame - version 1.0 1996; version 9.29 updated December 7, 2012 [Pageauthor Houghton]