
| Communities Resolving Our Problems: the basic idea | ||
| [SUP: Sharing Problems] | [THINK: Guidance] | [LEAP: Solving Problems] |
|
|
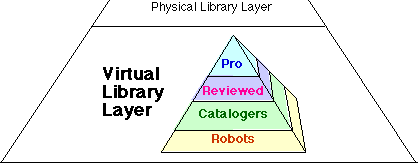 Guide to Effective Web SearchingIn the pyramid image above this paragraph, clicking on any of the layers in this image takes you to relevant online search tools. If you find too much information, narrow the search with AND and quotation mark techniques and if not enough information, broaden the search with OR technique. Some quick search tips are available to explain these concepts in more depth. If there is trouble in finding results, it is also helpful to know a few common problems. Numerous web sites and published books provide additional information (Yahoo Directory listing; Houghton, 1999; Amazon.com listing). The discussion below positions your search skills as a part of other key information processing steps and introduces you to the virtual layer of the information pyramid and many of its major features. These tools assume a mind with an interest in problem solving and an ability to ask questions. Searching for information is an important first step, but finding what you need is just part of a larger process. Once you have found it, you must qualify it. That is, the searcher should determine whether the information found on the Internet is reliable or authoritative and current. Since information can go from word processing file to globally published data without any review in seconds, this step of qualifying data requires special emphasis when weighing ideas from the Internet. Further information on the evaluation of online sources is available that can prevent you from passing along half-truths or outright nonsense and incorrect information which is readily available on the Internet. If your information passes the quality test, then process it. That is, problem solvers should include the new information with the knowledge that they already have in their digital outlines, concept maps and word processing documents as they carry out sequences of activities that lead to the solving of a problem or the completion of a task. The Virtual Library stands for data stored on networked hard drives which make up the Internet and other computer networks. An item found here is the real thing. By the real thing, I mean the full text or file that contains the entire story. This provides yet another name for this layer of information, the Thing Layer. In contrast to the hard drive storage of the world's Virtual or Thing Library, the Physical Library of the higher layer is made up of publications stored on millions of shelves located in tens of thousands of library buildings and organizational archives around the world. Though this writing focuses on features of the Virtual Library, there are other important contrasting features between this third layer and the second Physical Library layer. Where the online tools of the higher Physical Library layer find just the address or place of the document, such as its card catalog or shelf number, the tools of the Virtual layer retrieve the thing itself. Ultimately, our Physical Library stores its items as works that can physically be touched and handled and labels them with location or catalog numbers. It puts only the index to these works on the Internet. In contrast, our Virtual Library system puts both its index and the works that it indexes on the Internet. The four levels of the Virtual Library pyramid use path names to retrieve computer files, whether these files be text, images, audio or video. Path names indicate the location of the hard drive as well as the location on the file on that hard drive. |
| pyramid of information | Though the procedure to search, qualify and process information is relevant to all three layers of our global culture's pyramid of information, the requirement to qualify information takes on an even more significant role in the virtual layer. This base of these three layers, the virtual or hard drive layer, is also of such complexity and scale that it needs its own sub-pyramid of information tools to guide its use. The Internet, especially the Web (the World Wide Web), make up a significant and growing part of this layer. Because of the changeable and flexible nature of this layer, special emphasis must be put on qualifying information found in this layer. This pyramid serves as a model to help you more efficiently work through the complexity. It does so by suggesting a top-down strategy to use in tackling the pyramid. Problem solvers and other searchers should once again begin with the tools at the top of the pyramid and work downward. |
|
|
Degree of Human JudgmentThis bottom layer of the Look pyramid, the virtual layer, can also be organized as a collection of prioritized tools for searching. In this case, the priority is based on the degree of human judgment involved in the editing or refereeing of the stored information.The Virtual Library Pyramid: The Things Layer puts the Pro level at the top to represent the best view. It should also be noted that the top section takes up less space than any other part of the pyramid just as the percentage of Pro level materials is smaller than any other layer of Internet data. The Pro level represents full-text commercially published electronic files. Because of the higher level of human judgment involved in the commercial publishing process, these works generally provide the highest level of human judgment to the the files found on the Internet. There are three additional levels. The links at the Reviewed section of the virtual pyramid let you search databases of the most highly reviewed and qualified web pages. The Catalogers section of search tools shows those sites that do less reviewing but a great deal of advanced organizing into categories. The Robot section of the virtual pyramid takes you to links that do no reviewing or qualifying of what they put in their databases. Generally, the biggest databases are at the bottom of the Internet pyramid and the smallest at the top. But one of the points of the virtual pyramid is that a bigger quantity is not necessarily better. This pyramid suggests a general search strategy for problem solvers trying to find information. Start at the top of the virtual libray pyramid. Work from the highest levels of evaluation to the lowest. First use those search systems that have included the greatest degree of human judgment. For example, use the refereed indexes before you use a cataloger search tool. If you find what you need through tools at the top of the virtual pyramid, you have saved significant time and energy. If your search at higher levels of the pyramid comes up empty, move down the levels, through the subject catalogers, and eventually to the robot based systems with the fastest procedures for adding information. Do not interpret this to mean that the robot based systems are bad or poorly designed. To the contrary, they are fast and comprehensive. But they require much more work on your part in sifting out the most valuable items. Effective searchers must learn to maximize the features of the entire range of systems. For example, automated database construction through software robots builds enormous indexes or databases quickly. It is perhaps the only strategy that can almost keep up with the dramatic growth and change rates of the Internet. When you search these robot or automated indexes, search software puts the most relevant items at the top of your list by using formulas, such as counting the number of times your search terms appear in a web page. This strategy maximizes finding some quantity of information, of getting your hands on the needle in the haystack. The strategy however crumbles in attacking a topic for which massive amounts of information are already available on the Internet. A simple single word search might return 10,000 needles, that is references or links to web pages. Software robots can count word frequency and related tricks and put the sites or pages with the highest counts at the top of your returned list of sites. This helps. But the robots' statistical formulas are incapable of deeper analysis. They cannot rank pages based on higher values (e.g., the most accurate, easiest to use, or clearest writing style, etc.). Such higher filtering and rating systems take much longer to develop and cost much more in human time and resources. More costly development means that the most valuable refereed indexes may contain the fewest references and become the least current, depending on the economic resources of the reviewing or refereeing corporation. To apply significant amounts of qualified human intelligence is expensive. Consequently it seems reasonable to expect highly refereed indexes that are large and current will charge you at some point in their development or else go bankrupt and disappear. With any search system on this table above, information retrieved must be qualified. Your human judgment must be used to determine its truthfulness, relevance and its currency. |
|
|
Teachers and other adults responsible for children must
apply their own degrees of human judgment. Libraries have always segregrated
children's works from adult publications in different rooms. Such a protective
division is much harder to come by on the Internet. Depending on the search
terms used, items retrieved can be inappropriate in various degrees for
different levels of K-12 classrooms. Some site publications are totally
inappropriate at all times, perhaps because of their sexual connotation
or their sponsorship by hate groups. Sometimes the labels for the links
or web addresses can be deliberately misleading. Given the numbers of homes
acquiring Internet access, schools needs to educate parents as well as
implement plans for acceptable use policies in their school buildings.
Even city libraries need policies such as Houston's Rules for Online Safety.
Various products and companies provide tools that automatically screen out sites deemed inappropriate for children. To understand their potential it is useful to read reviews of these different software programs. They are not foolproof, but they provide a significant defense. These Internet filters also raise age-old concerns about well-meaning attempts to protect children that instead keep them from ideas they should encounter. Libraries have long lists of books that have been banned over the decades by one interest group or another. Where questions arise, long standing library policy has been to use a committee of community members to develop community standards. This same strategy can be used in issues that emerge related to the Internet and local schools. The Internet is a treasure trove of useful resources for school age classrooms. Informed educators need to work with their parents and other community members to think through the implications of various strategies that bring information age resources to their schools. Increasingly in the years ahead all types of information will be delivered most efficiently at lowest cost through electronic networks. Special Features for SearchingThe same search strategies that apply to the Physical layer apply to the Virtual layer. Searching strategies can be broken into two broad categories, simple and compound. In a simple search, you type in a single word and the search system or engine retrieves as many records that contain that word. When you search for "cat" thousands of web pages are available. Each search system however will provide different ways and degrees of compound searching. The searcher must carefully read the help screens at each system's site to make the most of its options.Compound searches use Boolean logic and other search techniques. Boolean involves AND, OR and NOT. That is to say, if you search for references to cats AND dogs and then do a second search using cats OR dogs, you will retrieve far more records with the second search strategy. In the first, both the word cats and the word dogs must be present in the record or reference for it to be retrieved and displayed. The second search strategy requires only one of the words to be present. The term NOT eliminates records. That is, a search for girls NOT women or woman would in theory bring up records that concentrate more on younger people. The advanced search help screens at various sites will teach you valuable techniques for obtaining better quality searches. Better quality searches require the use of many different kinds of techniques. These include: proximity, weighting, phrase, type, truncation, and rating level. The search engines are constantly developing new techniques and terms to help you become more efficient. Consequently, the terms below are only a partial list of what is available. Proximity techniques let you define how many characters apart certain words can be. As an example of the need for proximity searching, the author of a web page might write the phrase "the syrup from the maple tree" as a part of a longer sentence. If you search for the terms maple syrup the search engine may not find the string of characters. In a proximity search you can have the search engine look for maple within five terms of the word syrup. This increase the odds that you will get articles about maple syrup, not articles just about maple trees or just about some other syrup or be told that no such references existed. Weighting techniques allow the searcher to assign relative point totals to different terms to show that some terms are much more important than others when references are retrieved. Phrase searching counters the common default of treating each word in a set of words as part an OR search. This technique forces the search systems to retrieve references only when they completly match the set of words precisely. The term parts means that you can search just parts of documents, such as web address, title or body of document. Type means that the search can specify searches of different Internet systems for the storage of information, such as World Wide Web, telnet and gopher. Truncation allows the search system to find characters that are embedded in other words, such as searching for educat in order to find educational, educator and education. At some sites truncation is automatic and at others you must manually indicate how it should be done. Rating level requires the system to have rated the documents or sites that it stores in its index or database. Then given a specific rating system, the searcher can specify the rating levels that are allowable. Concept searching means that the search term you entered will be compared with a thesaurus of other terms which have similar meanings to your term. These other terms from the thesaurus will also be used to extend your search. This happens automatically in such systems as Excite and Northern Lights. Other systems search for just your term or variations of the term's word endings such as adding the letter "s" and tense such as "ed" and other options. How Is Acquisition Accomplished?Information databases constantly must acquire new entries to stay current. There are two general means of adding pages or Internet sites to an online index or search system: software robots add them automatically or people add them manually.The fastest way to do this which requires the least effort by human beings is to use software algorithms or software robots (e.g., spiders or bots). These specialized programs constantly updated their databases as they comb the net for sites and files not in their index or pages that have been updated since their last pass. This is why robot systems have indexed hundreds of millions more web pages that manually oriented operations. Providing evaluation in greater depth requires the development of criteria, criteria too complex for robotic formulas, and then the selection of human beings with sufficient knowledge to judge information, pages and sites based on those criteria. All of this is made slightly more complex in that robotic driven systems still allow human beings to manually submit items to their indexes, and people driven systems use robots to find new sites to evaluate and consider for inclusion in their more specialized and refereed databases. Judging: Rating the Referees and the ContentWho determines what should be placed in the web databases that you search?We have no system at the moment for comparing the reviewers at different companies, but the sites requiring reviewers to rate pages use different approaches that range from selecting experts who volunteer to professional writers to paying content experts. The databases maintained by the catalogers of the pyramid use a pool of employees to sift and categories sites. These employees are likely to be generalists, concentrating more on how to categorize a site than they are concerned about the quality of the content. The system at the bottom of the thing pyramid is to use a programmer's automated program, a computer formula that identifies new or updated files and automatically adds them to their database. |
|
|
How do you determine whether what you found is accurate
and truthful? You increase the odds of finding quality information, by
using sites toward the top of the thing pyramid which use greater degrees
of human judgment. If you cannot find someone else's expertise to guide
you, then you will have to develop your own. That is, you need to use a
range of critical thinking skills to evaluate the web sites that appear
valuable to you.
Annotation of the Items When Results of a Search are ReturnedSome sites simply list the web sites that were found. This greatly speeds up the time it takes to display relevant web sites. However, it is far easier to judge which link you would like to pursue if some additional text accompanies or annotates the returned addresses. Automated annotations may also include a relevancy ranking used to sort the items in importance to the user, a web address, date and file size.Professionally ReviewedSome sites have hired individuals to review and write professional comments and annotation evaluating and summarizing web sites. This extremely valuable service takes time and only a small portion of the web has been reviewed. Searching just the reviewed sites acts as a filter to keep away from sites that are poorly constructed and maintained.Subject CatalogsOther search and indexing systems hire professional catalogers or manage volunteers. They are not responsible for fully evaluating a web site, but are required to put groups of web sites together that fit into logical hierarchies of categories. This takes much less time than reviewing, but only a small portion of the Internet has been cataloged in this way.There are many different indexing or cataloging arrangements in use. The Dewey Decimal System, a standard for public school libraries, is one system divided all publications into major categories. The Library of Congress is another, a system used by most college and university libraries. In a similar way, those trying to index the web have created their own categories through which they organized all web pages. Yahoo was the first to develop their own significant system of online categories of information. Some search sites are following Yahoo's lead in developing their own categories for Internet information. The largest of these projects, the Open Directory Project (ODP), is volunteer based. As of September 23, 2003, the ODP reports that over 58,717 editor volunteers have cataloged over 3.8 million sites among over 460,000 categories. THE ODP powers the directories of Google, Hotbot, Netscape and Lycos, among others. In contrast, the commercial catalogers such as LookSmart and Yahoo employ only just a couple hundred employees each and come in respectively second and third in size. The count of the number of sites cataloged and how many categories are used by each company is not readily available, even by self-report from the companies' web pages. By hiring employees as indexers these companies should gain higher quality control but that presumption has not been tested to my knowledge. There is some evidence to support this thought. Using 2001 data for comparison, the more than 200 full time employees of LookSmart had cataloged nearly as many web sites as had the 36,000 part-time volunteer editors of ODP (2.5 million vs. 2.6 million). Robot ClassificationRobots in this context refers to computer software. All day and night these software agents wander the Internet by following web page links. They compare what they find with what is already in the database. When they come across a new or updated web page they send back the information to the master database. That is they can copy every word on the page, build an index of the words, and store this information. In this manner several robot sites have built the most comprehensive databases of the Internet. They include up to several billion records of web pages. In spite of the significant size of many search engines, the overlap or duplication among the search engines is only around fifty percent by some estimates. That is, in comparing search results from different search engines using the same search terms, over fifty percent of the hits or records will be unique to a given search engine. This means that it is very worth while to search in more than one search engine; what one cannot find, the next one might.Using 2003 data, Google.com is the current market leader. But size,
though important for search engines, is not everything. To evaluate these
software robots more carefully, several criteria are useful: the relative
size of the database; the freshness or frequency with with the search engine
checks for updates on the millions of web servers; growth rate of the database;
unique hits ability in finding the unusual or rare page; and dead link
count.
SummaryIn review, start at the top of the virtual library pyramid and work download through the four layers if necessary to find the information needed. But these are just technical skills. The underlying issue is one of human spirit. How are people who ask questions different than those who do not? How must we teach each other so that we have the interest to actively and persistently work to solve our own problems and those of others? |
Robot Site Reviews and Tutorials.
Further Indexes to Search Engine Information
|
|
| [ Updated December 18, 2003 | Parent Frame | Page author - Houghton] |